function foo() {
var myName = "极客时间"
let test1 = 1
const test2 = 2
var innerBar = { setName:function(newName){ myName = newName },
getName:function(){ console.log(test1) return myName } }
return innerBar}
var bar = foo()
bar.setName("极客邦")
bar.getName()
console.log(bar.getName())
站在内存模型的角度来分析这段代码的执行流程。 1.当 JavaScript 引擎执行到 foo 函数时,首先会编译,并创建一个空执行上下文。 2.在编译过程中,遇到内部函数 setName,JavaScript 引擎还要对内部函数做一次快速的词法扫描,发现该内部函数引用了 foo 函数中的 myName 变量,由于是内部函数引用了外部函数的变量,所以 JavaScript 引擎判断这是一个闭包,于是在堆空间创建换一个“closure(foo)”的对象(这是一个内部对象,JavaScript 是无法访问的),用来保存 myName 变量。 3.接着继续扫描到 getName 方法时,发现该函数内部还引用变量 test1,于是 JavaScript 引擎又将 test1 添加到“closure(foo)”对象中。这时候堆中的“closure(foo)”对象中就包含了 myName 和 test1 两个变量了。 4.由于 test2 并没有被内部函数引用,所以 test2 依然保存在调用栈中。通过上面的分析,我们可以画出执行到 foo 函数中“return innerBar”语句时的调用栈状态,如下图所示:
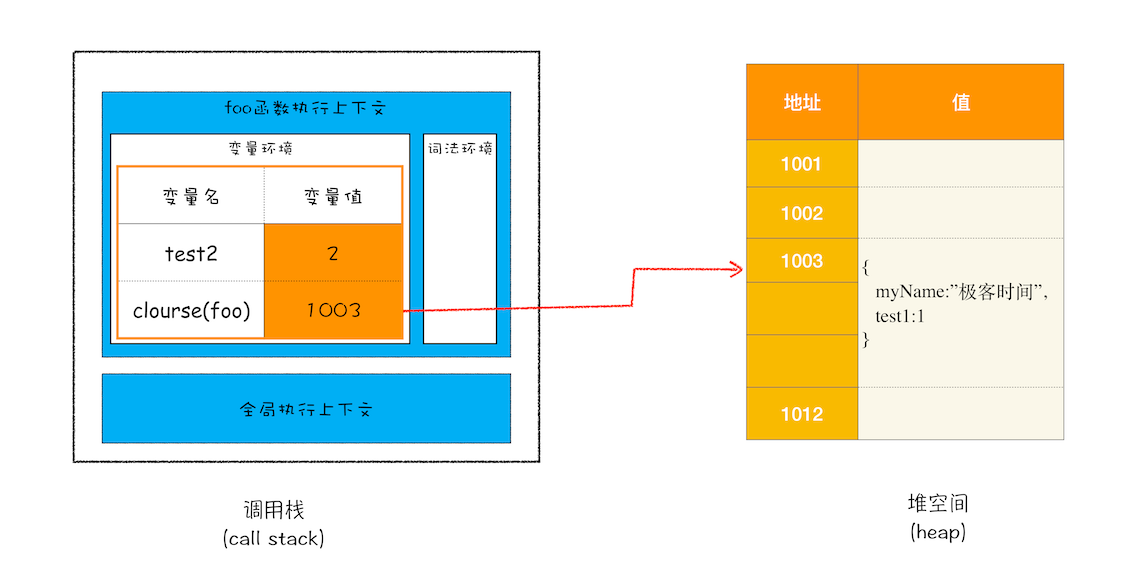
从上图你可以清晰地看出,当执行到 foo 函数时,闭包就产生了;当 foo 函数执行结束之后,返回的 getName 和 setName 方法都引用“clourse(foo)”对象,所以即使 foo 函数退出了,“clourse(foo)”依然被其内部的 getName 和 setName 方法引用。所以在下次调用bar.setName或者bar.getName时,创建的执行上下文中就包含了“clourse(foo)”。总的来说,产生闭包的核心有两步:第一步是需要预扫描内部函数;第二步是把内部函数引用的外部变量保存到堆中。